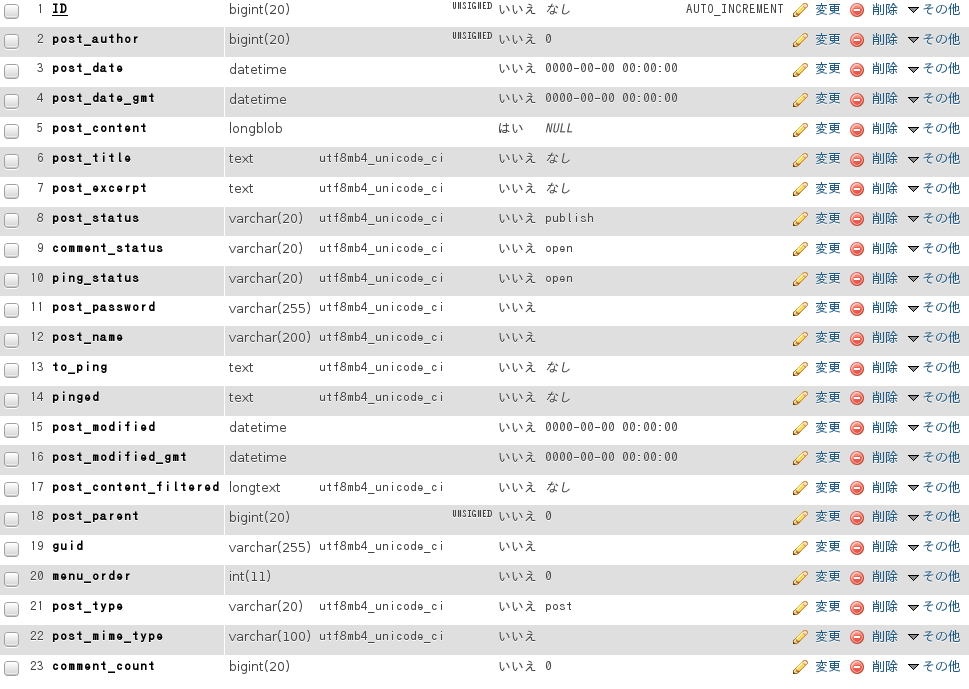
いやはやつかれました。ようやくおおよそ元に戻りました。utf8 がこんなに難しいって知りませんでした。SQLのALTERで COLLATE 変えると簡単に変わると思ったんだけど、一度 LONGBLOB, NULL に変えて、LONGTEXT, UTF8_UNICODE_CI に戻さなきゃなんないなんて、気がつかないよ、、、
というわけで、まだ変なキャラクターが出てくるかもしれませんが、ご容赦を。
Pretty tired with Japanese character codes. I think this is our characteristic not to drastically unify existing rules, but try to compromise among them… I mean why we cannot throw away the ancient Kanji codes, such as ISO-2022-JP or EUC or whatsoever?